From Document Jungle to Data Oasis: How LlamaIndex Helps Transform Data
May 28, 2024
May 28, 2024
May 28, 2024

Introduction to LlamaIndex
LLamaIndex is a Python library that allows you to create and query indexes over unstructured data using large language models (LLMs). Its primary purpose is to enable natural language querying of text data, making it easier to search and retrieve relevant information from various sources, such as documents, websites, and databases.
The primary motivation behind using LLamaIndex is to leverage the power of LLMs to work with unstructured data effectively. It enables accessing and querying data in a more natural and accessible way, improving productivity and enabling advanced applications like chatbots, virtual assistants, and knowledge management systems.
By bridging the gap between unstructured data and natural language, LLamaIndex provides a powerful tool for organizations and individuals to extract insights from diverse data sources using the capabilities of LLMs.
Watch the Demo
From unstructured to structured data…
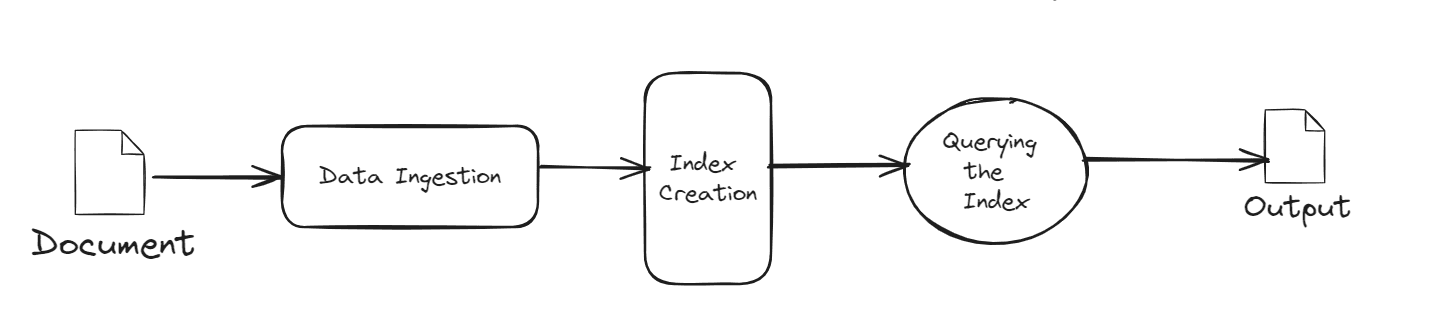
As illustrated in the diagram above, the process begins with uploading a document into the database. Once uploaded, the system creates indexes for all the data, each with a limited capacity. After indexing, users can query these indexes with any questions they have regarding the data. The final step is to display the output generated from these queries.
Simplifying Data Management with LlamaIndex: A Step-by-Step Journey
Imagine a bustling sales company, SalesCo, which has mountains of sales reports, customer feedback, and market research documents. SalesCo’s goal is to efficiently manage and retrieve relevant information to enhance sales strategies and improve customer service. This is where LlamaIndex comes in, revolutionizing the way they handle data.
Let’s embark on this journey with SalesCo to see how LlamaIndex transforms their data management process.
Data Ingestion: Collecting and Structuring the Data
Step 1: Gathering Data
SalesCo collects data from various sources: sales reports in text files, customer feedback in PDFs, market research documents in Word, and presentations in PowerPoint. Additionally, they have data stored in SQL and NoSQL databases.
Step 2: Parsing Data
Using LlamaIndex’s 'Reader' classes, SalesCo converts these documents into a structured format. Think of it as sorting through a giant pile of mail and organizing each piece into clearly labeled bins. Text files, PDFs, and database entries are all parsed and transformed into Document objects, ready for indexing.
Step 3: Preparing for Indexing
With all data parsed, it’s now structured and neatly organized, just like how a librarian categorizes books before placing them on shelves. These Document objects are now ready for the next step.
Index Creation: Building an Efficient Retrieval System
Step 1: Choosing the Index Type
SalesCo decides on the most suitable indexing method. For their needs, they choose the VectorStoreIndex, which is ideal for managing large datasets and ensuring quick retrieval of information.
Step 2: Creating the Index
They set a chunk size to determine how text is split for indexing. Picture it like slicing a large cake into smaller, manageable pieces. SalesCo chunks their documents and creates an index for each year’s documents, storing these indices in a structured, easy-to-access manner.
Step 3: Persisting the Index
To ensure that all this hard work isn’t lost, SalesCo saves the indices to disk. It’s like creating a digital filing cabinet where each folder is neatly labeled and stored for future use.
Generating Embeddings: Understanding the Content
Step 1: Generating Embeddings
Now, SalesCo needs to ensure their system understands the meaning of the text. LlamaIndex leverages pre-trained language models to create embeddings—dense vector representations that capture the semantic essence of each text chunk. Imagine these embeddings as a smart librarian who not only knows where each book is but also understands its content deeply.
Step 2: Storing Embeddings
These embeddings are stored in a way that allows for efficient retrieval. It’s like having a detailed map of a library where each section and shelf is precisely indexed for quick access.
Querying the Index: Retrieving Relevant Information
Step 1: Formulating the Query
A sales manager at SalesCo needs to find the latest customer feedback on a specific product. They use a natural language query, asking the system in plain English to retrieve relevant documents.
Step 2: Retrieving Data
The system uses the pre-trained language model to understand the query, searches through the indices, and retrieves the most relevant documents. It’s like asking the smart librarian for a book on a topic and getting handed exactly what you need, along with a few other useful resources.
Step 3: Presenting Results
The retrieved information is presented in a clear and concise manner. The sales manager receives a synthesized summary of the feedback, enabling quick and informed decision-making.
Bringing it All Together
By following this process, SalesCo has transformed their data management system. They can now efficiently ingest data from various sources, create comprehensive indices, generate meaningful embeddings, and retrieve information quickly and accurately. This streamlined approach not only saves time but also enhances their sales strategies and customer service.
With LlamaIndex, SalesCo has turned a daunting task into a seamless, efficient operation, demonstrating the power of modern AI in solving real-world challenges. Whether you’re in sales, healthcare, or any other field, LlamaIndex can help you manage and leverage your data effectively, driving better outcomes and smarter decisions.
Conclusion
The combination of data ingestion, flexible indexing techniques, and powerful querying capabilities makes LlamaIndex a versatile tool for applications like knowledge management and information retrieval. Proper data structuring ensures that the information fed into Large Language Models (LLMs) is of the highest quality, directly impacting their performance and accuracy.
Effective data management with tools like LlamaIndex is crucial for achieving excellent AI results. By ensuring your data is well-organized and accurately indexed, you enable your LLMs to deliver precise and reliable insights, highlighting the essential role of quality data in AI success.
Sources
Introduction to LlamaIndex
LLamaIndex is a Python library that allows you to create and query indexes over unstructured data using large language models (LLMs). Its primary purpose is to enable natural language querying of text data, making it easier to search and retrieve relevant information from various sources, such as documents, websites, and databases.
The primary motivation behind using LLamaIndex is to leverage the power of LLMs to work with unstructured data effectively. It enables accessing and querying data in a more natural and accessible way, improving productivity and enabling advanced applications like chatbots, virtual assistants, and knowledge management systems.
By bridging the gap between unstructured data and natural language, LLamaIndex provides a powerful tool for organizations and individuals to extract insights from diverse data sources using the capabilities of LLMs.
Watch the Demo
From unstructured to structured data…
As illustrated in the diagram above, the process begins with uploading a document into the database. Once uploaded, the system creates indexes for all the data, each with a limited capacity. After indexing, users can query these indexes with any questions they have regarding the data. The final step is to display the output generated from these queries.
Simplifying Data Management with LlamaIndex: A Step-by-Step Journey
Imagine a bustling sales company, SalesCo, which has mountains of sales reports, customer feedback, and market research documents. SalesCo’s goal is to efficiently manage and retrieve relevant information to enhance sales strategies and improve customer service. This is where LlamaIndex comes in, revolutionizing the way they handle data.
Let’s embark on this journey with SalesCo to see how LlamaIndex transforms their data management process.
Data Ingestion: Collecting and Structuring the Data
Step 1: Gathering Data
SalesCo collects data from various sources: sales reports in text files, customer feedback in PDFs, market research documents in Word, and presentations in PowerPoint. Additionally, they have data stored in SQL and NoSQL databases.
Step 2: Parsing Data
Using LlamaIndex’s 'Reader' classes, SalesCo converts these documents into a structured format. Think of it as sorting through a giant pile of mail and organizing each piece into clearly labeled bins. Text files, PDFs, and database entries are all parsed and transformed into Document objects, ready for indexing.
Step 3: Preparing for Indexing
With all data parsed, it’s now structured and neatly organized, just like how a librarian categorizes books before placing them on shelves. These Document objects are now ready for the next step.
Index Creation: Building an Efficient Retrieval System
Step 1: Choosing the Index Type
SalesCo decides on the most suitable indexing method. For their needs, they choose the VectorStoreIndex, which is ideal for managing large datasets and ensuring quick retrieval of information.
Step 2: Creating the Index
They set a chunk size to determine how text is split for indexing. Picture it like slicing a large cake into smaller, manageable pieces. SalesCo chunks their documents and creates an index for each year’s documents, storing these indices in a structured, easy-to-access manner.
Step 3: Persisting the Index
To ensure that all this hard work isn’t lost, SalesCo saves the indices to disk. It’s like creating a digital filing cabinet where each folder is neatly labeled and stored for future use.
Generating Embeddings: Understanding the Content
Step 1: Generating Embeddings
Now, SalesCo needs to ensure their system understands the meaning of the text. LlamaIndex leverages pre-trained language models to create embeddings—dense vector representations that capture the semantic essence of each text chunk. Imagine these embeddings as a smart librarian who not only knows where each book is but also understands its content deeply.
Step 2: Storing Embeddings
These embeddings are stored in a way that allows for efficient retrieval. It’s like having a detailed map of a library where each section and shelf is precisely indexed for quick access.
Querying the Index: Retrieving Relevant Information
Step 1: Formulating the Query
A sales manager at SalesCo needs to find the latest customer feedback on a specific product. They use a natural language query, asking the system in plain English to retrieve relevant documents.
Step 2: Retrieving Data
The system uses the pre-trained language model to understand the query, searches through the indices, and retrieves the most relevant documents. It’s like asking the smart librarian for a book on a topic and getting handed exactly what you need, along with a few other useful resources.
Step 3: Presenting Results
The retrieved information is presented in a clear and concise manner. The sales manager receives a synthesized summary of the feedback, enabling quick and informed decision-making.
Bringing it All Together
By following this process, SalesCo has transformed their data management system. They can now efficiently ingest data from various sources, create comprehensive indices, generate meaningful embeddings, and retrieve information quickly and accurately. This streamlined approach not only saves time but also enhances their sales strategies and customer service.
With LlamaIndex, SalesCo has turned a daunting task into a seamless, efficient operation, demonstrating the power of modern AI in solving real-world challenges. Whether you’re in sales, healthcare, or any other field, LlamaIndex can help you manage and leverage your data effectively, driving better outcomes and smarter decisions.
Conclusion
The combination of data ingestion, flexible indexing techniques, and powerful querying capabilities makes LlamaIndex a versatile tool for applications like knowledge management and information retrieval. Proper data structuring ensures that the information fed into Large Language Models (LLMs) is of the highest quality, directly impacting their performance and accuracy.
Effective data management with tools like LlamaIndex is crucial for achieving excellent AI results. By ensuring your data is well-organized and accurately indexed, you enable your LLMs to deliver precise and reliable insights, highlighting the essential role of quality data in AI success.
Sources
Lets build something
great together!
📞 Phone: +91-8329284312
📧 Email: contact@hackerox.com
📍Address:
Malad West, Mumbai - 400064
Lets build something
great together!
📞 Phone: +91-8329284312
📧 Email: contact@hackerox.com
📍Address: Malad West, Mumbai - 400064
Lets build something
great together!
📞 Phone: +91-8329284312
📧 Email: contact@hackerox.com
📍Address: Malad West, Mumbai - 400064