Comparing Methods for Extracting Table Data from PDFs: An In-Depth Analysis
May 29, 2024
May 29, 2024
May 29, 2024

Overview of PDF Text Extraction from Table
By combining PDF processing libraries with Llama Indexing, we can efficiently extract and index text from tables in PDF documents. This approach allows for robust data retrieval, making it easier to analyze and work with tabular data extracted from PDFs.
In this blog we will demonstrate how to leverage the Table Transformer model in conjunction with GPT4-V to yield better results for images containing tables.
Demo: PDF Text Extraction
Let's weigh our options…
There are 4 different ways with which data can be extracted from tables
Retrieving relevant images (PDF pages) and sending them to GPT4-V to respond to queries.
Regarding every PDF page as an image, let GPT4-V do the image reasoning for each page. Build Text Vector Store index for the image reasonings. Query the answer against the Image Reasoning Vector Store.
Using Table Transformer to crop the table information from the retrieved images and then sending these cropped images to GPT4-V for query responses.
Applying OCR on cropped table images and sending the data to GPT4/ GPT-3.5 to answer the query.
Lets see the same with an architecture diagram
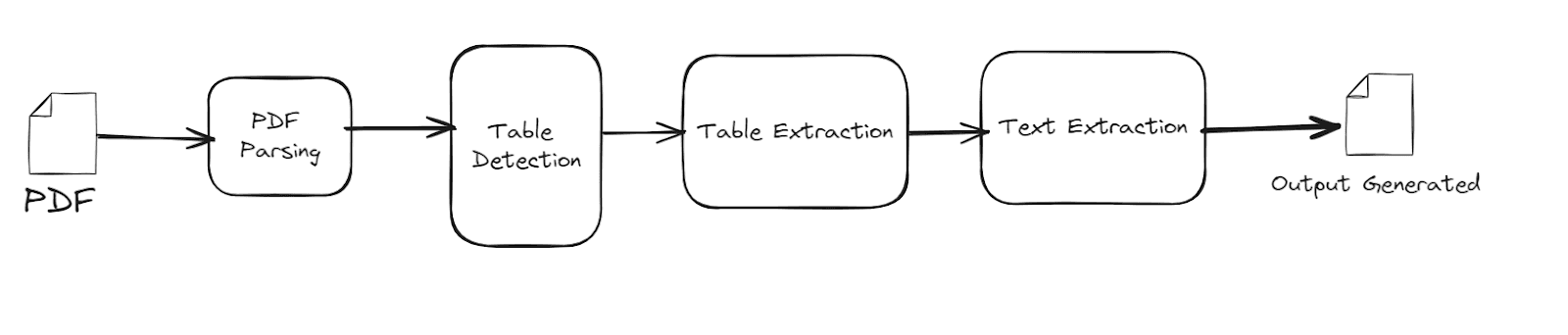
Method 1
The idea is to parse the PDF document and extract its internal structure, including text, images, and layout information. This involves analyzing the PDF's object streams and content streams to identify the different elements and their relationships.
The flow begins as parsing a PDF document, extracting each individual page, converting those pages into image format, and finally saving the converted images.

Conclusion
The result indicates that the model is unable to accurately compare and identify the functional entities within the images, leading to the failure to extract table information from PDFs.
Method 2
The next approach involves considering each PDF page as an image and utilizing GPT-4's visual reasoning capabilities to directly extract table data from these page images. The extracted table data is then indexed, allowing for subsequent text-based retrieval and querying of the indexed table information.
With this approach, we take the image of a single PDF page and feed it into a large language model (LLM). The LLM is then tasked with visually analyzing the page image to detect and extract any table data present. Once the table data is identified, we can proceed to query the LLM with our desired questions, leveraging its ability to reason over the extracted tabular information.

Conclusion
However, the results reveal that the model is unable to accurately identify and extract the precise table data from the given image, indicating the limitations of this approach..
Method 3
The next approach involves utilizing Microsoft's Table Transformer tool to crop and extract table regions from the PDF page images. The cropped table images will then be provided to the GPT model to evaluate its ability to accurately respond to queries based on the extracted tabular data.

Conclusion
The observations indicate that this approach yields the desired responses, demonstrating the model's ability to accurately answer queries when provided with the precisely extracted tabular information.
Method 4
In this approach, we apply Optical Character Recognition (OCR) on the cropped table images extracted from the PDF pages. OCR technology converts different types of documents, such as scanned paper documents, PDF files, or images captured by a digital camera, into editable and searchable data. This allows us to extract textual data from images of tables.
Once the OCR process is complete, the extracted textual data is passed to a large language model (LLM) like GPT-4 or GPT-3.5. The LLM is then used to answer queries based on the extracted tabular data.

Conclusion
The accuracy of the OCR process on the cropped table images is not satisfactory, leading to discrepancies between the extracted data and the original table content.
The best method is…
After evaluating various methods, the best approach is utilizing Optical Character Recognition (OCR) on cropped table images. OCR accurately converts table data from images into machine-readable text, enhancing searchability and usability. Integrating this data with GPT models leverages their powerful language processing capabilities, allowing for sophisticated querying and accurate responses. This method combines accuracy, efficiency, and flexibility, making it the most effective solution for extracting and querying table data from PDFs.
Conclusion
Effective data management is crucial for achieving high-quality results with AI models. LlamaIndex, combined with robust methods for extracting and structuring data, ensures that your large language models receive precise and organized information.
Whether through OCR on table images or other advanced techniques, structuring your data properly is key to unlocking the full potential of your AI solutions. By leveraging these methods, you can drive better outcomes and smarter decisions, showcasing the importance of quality data in AI success.
Sources
Overview of PDF Text Extraction from Table
By combining PDF processing libraries with Llama Indexing, we can efficiently extract and index text from tables in PDF documents. This approach allows for robust data retrieval, making it easier to analyze and work with tabular data extracted from PDFs.
In this blog we will demonstrate how to leverage the Table Transformer model in conjunction with GPT4-V to yield better results for images containing tables.
Demo: PDF Text Extraction
Let's weigh our options…
There are 4 different ways with which data can be extracted from tables
Retrieving relevant images (PDF pages) and sending them to GPT4-V to respond to queries.
Regarding every PDF page as an image, let GPT4-V do the image reasoning for each page. Build Text Vector Store index for the image reasonings. Query the answer against the Image Reasoning Vector Store.
Using Table Transformer to crop the table information from the retrieved images and then sending these cropped images to GPT4-V for query responses.
Applying OCR on cropped table images and sending the data to GPT4/ GPT-3.5 to answer the query.
Lets see the same with an architecture diagram
Method 1
The idea is to parse the PDF document and extract its internal structure, including text, images, and layout information. This involves analyzing the PDF's object streams and content streams to identify the different elements and their relationships.
The flow begins as parsing a PDF document, extracting each individual page, converting those pages into image format, and finally saving the converted images.
Conclusion
The result indicates that the model is unable to accurately compare and identify the functional entities within the images, leading to the failure to extract table information from PDFs.
Method 2
The next approach involves considering each PDF page as an image and utilizing GPT-4's visual reasoning capabilities to directly extract table data from these page images. The extracted table data is then indexed, allowing for subsequent text-based retrieval and querying of the indexed table information.
With this approach, we take the image of a single PDF page and feed it into a large language model (LLM). The LLM is then tasked with visually analyzing the page image to detect and extract any table data present. Once the table data is identified, we can proceed to query the LLM with our desired questions, leveraging its ability to reason over the extracted tabular information.
Conclusion
However, the results reveal that the model is unable to accurately identify and extract the precise table data from the given image, indicating the limitations of this approach..
Method 3
The next approach involves utilizing Microsoft's Table Transformer tool to crop and extract table regions from the PDF page images. The cropped table images will then be provided to the GPT model to evaluate its ability to accurately respond to queries based on the extracted tabular data.
Conclusion
The observations indicate that this approach yields the desired responses, demonstrating the model's ability to accurately answer queries when provided with the precisely extracted tabular information.
Method 4
In this approach, we apply Optical Character Recognition (OCR) on the cropped table images extracted from the PDF pages. OCR technology converts different types of documents, such as scanned paper documents, PDF files, or images captured by a digital camera, into editable and searchable data. This allows us to extract textual data from images of tables.
Once the OCR process is complete, the extracted textual data is passed to a large language model (LLM) like GPT-4 or GPT-3.5. The LLM is then used to answer queries based on the extracted tabular data.
Conclusion
The accuracy of the OCR process on the cropped table images is not satisfactory, leading to discrepancies between the extracted data and the original table content.
The best method is…
After evaluating various methods, the best approach is utilizing Optical Character Recognition (OCR) on cropped table images. OCR accurately converts table data from images into machine-readable text, enhancing searchability and usability. Integrating this data with GPT models leverages their powerful language processing capabilities, allowing for sophisticated querying and accurate responses. This method combines accuracy, efficiency, and flexibility, making it the most effective solution for extracting and querying table data from PDFs.
Conclusion
Effective data management is crucial for achieving high-quality results with AI models. LlamaIndex, combined with robust methods for extracting and structuring data, ensures that your large language models receive precise and organized information.
Whether through OCR on table images or other advanced techniques, structuring your data properly is key to unlocking the full potential of your AI solutions. By leveraging these methods, you can drive better outcomes and smarter decisions, showcasing the importance of quality data in AI success.
Sources
Lets build something
great together!
📞 Phone: +91-8329284312
📧 Email: contact@hackerox.com
📍Address:
Malad West, Mumbai - 400064
Lets build something
great together!
📞 Phone: +91-8329284312
📧 Email: contact@hackerox.com
📍Address: Malad West, Mumbai - 400064
Lets build something
great together!
📞 Phone: +91-8329284312
📧 Email: contact@hackerox.com
📍Address: Malad West, Mumbai - 400064